Não é nenhum segredo que o ChatGPT da OpenAI tem alguns recursos incríveis – por exemplo, o chatbot pode escrever poesia que se assemelha a sonetos de Shakespeare ou depurar código para um programa de computador. Essas habilidades são possibilitadas pelo enorme modelo de aprendizado de máquina no qual o ChatGPT é construído. Os pesquisadores descobriram que, quando esses tipos de modelos se tornam grandes o suficiente, surgem capacidades extraordinárias.
Mas modelos maiores também exigem mais tempo e dinheiro para treinar. O processo de treinamento envolve mostrar centenas de bilhões de exemplos para um modelo. Reunir tantos dados é um processo complicado em si. Depois vêm os custos monetários e ambientais de operar muitos computadores poderosos por dias ou semanas para treinar um modelo que pode ter bilhões de parâmetros.
“Estima-se que os modelos de treinamento na escala em que o ChatGPT supostamente funciona podem custar milhões de dólares, apenas para uma única execução de treinamento. Podemos melhorar a eficiência desses métodos de treinamento, para que possamos obter bons modelos em menos tempo e por menos dinheiro? Propomos fazer isso aproveitando modelos de linguagem menores que foram previamente treinados”, diz Yoon Kim, professor assistente do Departamento de Engenharia Elétrica e Ciência da Computação do MIT e membro do Laboratório de Ciência da Computação e Inteligência Artificial (CSAIL).
Em vez de descartar uma versão anterior de um modelo, Kim e seus colaboradores a utilizam como base para um novo modelo. Usando o aprendizado de máquina, seu método aprende a “crescer” um modelo maior a partir de um modelo menor de uma forma que codifica o conhecimento que o modelo menor já adquiriu. Isso permite um treinamento mais rápido do modelo maior.
Sua técnica economiza cerca de 50 % do custo computacional necessário para treinar um modelo grande, em comparação com métodos que treinam um novo modelo do zero. Além disso, os modelos treinados com o método MIT tiveram um desempenho tão bom ou melhor do que os modelos treinados com outras técnicas que também usam modelos menores para permitir um treinamento mais rápido de modelos maiores.
Reduzir o tempo necessário para treinar modelos enormes pode ajudar os pesquisadores a fazer avanços mais rápidos com menos despesas, além de reduzir as emissões de carbono geradas durante o processo de treinamento. Também poderia permitir que grupos de pesquisa menores trabalhassem com esses modelos massivos, potencialmente abrindo as portas para muitos novos avanços.
“À medida que procuramos democratizar esses tipos de tecnologias, tornar o treinamento mais rápido e barato se tornará mais importante”, diz Kim, autor sênior de um artigo sobre essa técnica.
Kim e seu aluno de pós-graduação Lucas Torroba Hennigen escreveram o artigo com o principal autor Peihao Wang, aluno de pós-graduação da Universidade do Texas em Austin, bem como outros do MIT-IBM Watson AI Lab e da Columbia University. A pesquisa será apresentada na Conferência Internacional sobre Representações de Aprendizagem.
Quanto maior melhor
Grandes modelos de linguagem como o GPT-3, que está no centro do ChatGPT, são construídos usando uma arquitetura de rede neural chamada transformador. Uma rede neural, vagamente baseada no cérebro humano, é composta de camadas de nós interconectados, ou “neurônios”. Cada neurônio contém parâmetros, que são variáveis aprendidas durante o processo de treinamento que o neurônio usa para processar dados.
As arquiteturas de transformadores são únicas porque, à medida que esses tipos de modelos de rede neural aumentam, eles alcançam resultados muito melhores.
“Isso levou a uma corrida armamentista de empresas tentando treinar transformadores cada vez maiores em conjuntos de dados cada vez maiores. Mais do que outras arquiteturas, parece que as redes transformadoras ficam muito melhores com o dimensionamento. Só não sabemos ao certo por que esse é o caso”, diz Kim.
Esses modelos geralmente têm centenas de milhões ou bilhões de parâmetros que podem ser aprendidos. Treinar todos esses parâmetros do zero é caro, então os pesquisadores buscam acelerar o processo.
Uma técnica eficaz é conhecida como crescimento de modelo. Usando o método de crescimento do modelo, os pesquisadores podem aumentar o tamanho de um transformador copiando neurônios ou até camadas inteiras de uma versão anterior da rede e empilhando-os no topo. Eles podem tornar uma rede mais ampla adicionando novos neurônios a uma camada ou torná-la mais profunda adicionando camadas adicionais de neurônios.
Em contraste com as abordagens anteriores para o crescimento do modelo, os parâmetros associados aos novos neurônios no transformador expandido não são apenas cópias dos parâmetros da rede menor, explica Kim. Em vez disso, são combinações aprendidas dos parâmetros do modelo menor.
Aprendendo a crescer
Kim e seus colaboradores usam aprendizado de máquina para aprender um mapeamento linear dos parâmetros do modelo menor. Este mapa linear é uma operação matemática que transforma um conjunto de valores de entrada, neste caso os parâmetros do modelo menor, em um conjunto de valores de saída, neste caso os parâmetros do modelo maior.
Seu método, que eles chamam de Operador de Crescimento Linear aprendido (LiGO), aprende a expandir a largura e a profundidade de uma rede maior a partir dos parâmetros de uma rede menor de maneira orientada por dados.
Mas o modelo menor pode realmente ser muito grande – talvez tenha cem milhões de parâmetros – e os pesquisadores podem querer fazer um modelo com um bilhão de parâmetros. Portanto, a técnica LiGO divide o mapa linear em partes menores que um algoritmo de aprendizado de máquina pode manipular.
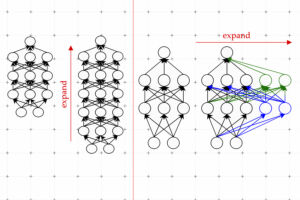
O LiGO também expande a largura e a profundidade simultaneamente, o que o torna mais eficiente do que outros métodos. Um usuário pode ajustar a largura e a profundidade que deseja que o modelo maior tenha ao inserir o modelo menor e seus parâmetros, explica Kim.
Quando compararam sua técnica com o processo de treinamento de um novo modelo a partir do zero, bem como com métodos de crescimento de modelo, foi mais rápido do que todas as linhas de base. Seu método economiza cerca de 50% dos custos computacionais necessários para treinar os modelos de visão e linguagem, ao mesmo tempo em que melhora o desempenho.
Os pesquisadores também descobriram que poderiam usar o LiGO para acelerar o treinamento do transformador, mesmo quando não tivessem acesso a um modelo pré-treinado menor.
“Fiquei surpreso com o quão melhor todos os métodos, incluindo o nosso, se saíram em comparação com a inicialização aleatória, linhas de base de treinamento a partir do zero.” diz Kim. Para saber mais sobre o modelo leia a matéria completa no site.
Para continuar por dentro das principais notícias do mundo da indústria acesse o nosso site.

